overview
The smallest operation unit supported by SCT database is a table, that is, there is no library concept;SCT database is based on columnar storage and supports C++ basic data structure types, including integer(Including u08, i08, u16, i16, u32, i32, u64, i64)、 float(Including float, double)、fixed-length string(Including string04, string08, string16, string32, string64, string128, string256)、date(date)、time(time)、 datetime(datetime).
Any field of SCT database implies an index based on a balanced tree, see create,The export and load statement or import statement in the sql statement support table export
and import.
Explanation:SCT database query language (hereinafter abbreviated as sql),similar to standard query language (hereinafter abbreviated as SQL),The basic syntax structure is compatible, and the overall processing flow is not compatible with SQL.
Note that the following SQL operation methods are different from standard SQL:
Features supported by SCT database:
Installation requirement
SCT database uses a certain amount of memory as a cache. The cache memory configuration can be used for different tables. It is recommended that the system retain at least about 2G of memory during installation. The SCT database data file is located in the sdb directory. It is recommended that the disk where the installation directory is located retain at least 10G of available hard disk space according to business requirements.
System requirements
SCT database can work normally on the following operating systems:
Windows 7, Windows 10, Windows server 2008 and above, Linux Debian 9, Linux Centos 7. Other distribution systems have not been fully tested, please ensure the above system environment when installing.
SCT database stores data as multiple files. For Linux system platforms, please ensure that the maximum number of open files in the system is greater than the data column requirements.
usage constraint
The maximum number of tables supported by the SCT database is 4096, the maximum number of fields in each table is 4096, and the maximum length of each field is 256.
The field name may be limited by the characters supported by the system. Please make sure that the field name is a valid file name when using it.
SCT database configuration files and import and export data (including sql statements or csv files) are in the default utf8 encoding, and the Unix system newline character is used as the end of the line.
SCT regular expression matching does not support .*backtracking matching.
By default, the maximum number of simultaneous network connections on the Linux platform is 16.
Installation and run
On the Windows platform, you can directly unzip the zip installation package file you purchased to the target directory.
On the Linux platform, directly unzip the gz installation package file you purchased to the target directory.
System composition
Windows system directory composition
The local version executable program sct_local.exe
Server executable program sct_s.exe
Client executable program sct_c.exe
Web version development kit sdk
Local version configuration file sct_ldb.toml
Network version configuration file sct_rdb.toml
The data file is located in the sdb directory
Linux system directory composition
The local executable program run_l.sh
The server executable program run_s.sh
Client executable program run_c.sh
Web version development kit sdk
Local version configuration file sct_ldb.toml
Network version configuration file sct_rdb.toml
The data file is located in the sdb directory
Startup method
Run the local version of the executable program directly in the local mode; after entering the execution environment, enter the "help" command to view the help information or directly enter the sql statement to execute. For the corresponding sql specification, see sql quick guide part.
A user name, password and optional IP port must be specified to run the network mode client. The following is a valid running example.
sct_c.exe user user_pwd
sct_c.exe user user_pwd 192.168.1.11 55555
The default network mode verification policy is that the user name and password must be specified for the first login, 3 errors stop for 1 minute, 2 errors stop for 30 minutes, 1 error stop for 15 days, and 1 error stop forever until The service restarts.
System configuration
The SCT database uses toml as the configuration file, and the local mode uses sct_ldb.toml as the configuration file. For toml file specifications, please refer to Related specifications, max_cache_level in the configuration file is the most important cache memory usage parameter, especially the read performance. It represents the number of levels of the BST tree cache, and the minimum is 0, which means that memory is not used.
The auto_cache parameter indicates whether the cache data is automatically loaded when the database is started. The default is automatic cache, auto_cache_ratio indicates the maximum tree height ratio of the cache, 0 means no cache at all, and 1 means full cache. Note that the cache will take a certain amount of time. For larger data tables, it is recommended not to cache an excessively large height ratio.
The cache_table parameter indicates that the cache size is set for a special table name.
The big_csv segment external_sort_count indicates the number of outbound rows when using the load big_csv command, and csv_read_once_size indicates the size of the csv file to be read at one time. For machines with small physical memory, you can adjust the corresponding parameters. The larger the parameter, the faster the load command will be executed.
The network mode server is sct_s.exe, and the server uses sct_rdb.toml as the configuration file. The configuration content is the binding port and user group information. Other configuration information such as cache is the same as the local mode database configuration content.
enable_write_cache indicates whether to enable write caching. Write caching is not enabled by default. Using write caching can effectively speed up data insertion, update, and deletion, but it may cause data loss when exiting the service abnormally.
write_cache_count indicates the maximum number of write caches for each field. The larger the number, the faster the write operation. It is recommended that the data should not be too large. The above fields can be omitted by default. If the corresponding configuration does not exist, the default configuration parameter value will be used.
sql specification
sql basic specification description
The sql statement is composed of DDL and DML, where DML is composed of
select,
insert,
delete,
update,
rows_of,
cols_of,
fields_of,
show tables, etc.; DDL consists of
create,
alter,
drop,
import,
load,
exec and other components.
Each sql statement non-constant expression or comment content can be followed by any number of blank or comment characters, blank characters are 0x09 to 0x0c (note that blank characters do not contain 0x0d, which means
that the end of the SQL statement execution line defaults to unix format ) Or 0x20 ASCII characters.
All sql statements are strictly case sensitive, and the character encoding is the only encoding UTF-8.
The terminator of each sql statement is ";", which can be omitted if it does not affect the parsing of the statement.
Comment
Single line comment:
//This is a comment
Multi-line comments:
/*This is
a comment
*/
Basic data type
integer
0 //Signed or unsigned integer
1 //Elliptical integer
100 //Elliptical integer
+1 //signed integer
-100 //signed integer
-1000 //signed integer
+0b000 //signed binary integer
-0xa0b3 //signed hexadecimal integer
0xA0cD //Unsigned mixed case hexadecimal integer
-847u2 //signed two-byte long integer
56u1 //Unsigned one-byte long integer
0x0au1 //Unsigned hexadecimal one-byte integerfloat
+0. //Positive floating point number without fractional part
-0.01 //Only decimal part negative floating point number
-100.0 //Only the integer part of the negative floating point number
-100e20 //Only integers and negative floating-point numbers with positive exponents
1.25E-32 //decimal and negative exponent part positive floating point number
1.25E+20 //decimal and positive exponent part positive floating point number
1.00E20f //strictly four-byte floating point number
1.00E20d //strict eight-byte floating point numberfixed-length string
Fixed-length character strings only support the following byte lengths: 4, 8, 16, 32, 64, 128, 256
"a和中文bc" //Contains valid strings in Chinese and English (UTF-8 encoding)
"ab和中文c\"\'\\\a\b\f\n\r\t\v" //Valid string containing control escape
"ab和中文c\x0a\x0001\uaabb\Uaabbccdd" //Valid string containing hexadecimal escape and Unicode escape
@"aabbcc(018d7##@!@^_""AA6)aabbcc" //Raw string separated by aabbccdate
2020-02-03 //February 3, 2020
0020-01-31 //January 31, 2020time
18:59:31 //18:59:31
00:00:01.100 //0 hours 0 minutes 1.1 secondsdatetime
2020-02-03 18:59:31.123 //February 3, 2020 18:59:31.123expression
The expression uses the C language expression basic structure and retains the priority of the corresponding
operation symbol
id //Domain expression represents the corresponding field value
(id) //The bracket expression indicates the evaluation of the priority bracket content
id+10 //additive expression represents the sum of the domain field and the constant value 10
id+max(grade) //additive expression represents the sum of the maximum value of the field field and the grade field
id*sin(id) //Integral expression represents the product of the sin value of id domain and id domain
id << 10 //The shift expression represents the value of the id field shifted by 10 bits to the left
id&&sin(id)>0 //The logical AND expression represents the logical AND result of id and sin(id)>0
id/sin(id) //Integral expression represents the quotient of id and sin(id)
id&min(id) //bits and expressions represent id and min(id) bits and results
id!=0||id==10 //Logical OR expression means the logical OR result of id not equal to 0 and id equal to 10
Expression type conversion and function processing follow the following principles
If the data type can be implicitly converted to the target type according to the C++ language, then it is
implicitly converted to the target type according to C++.
The function processing process is: if the function parameter is a field, the function acts on the value of each
row of the field; if the function parameter is a constant value, the constant value is used as the function
parameter; if the number of rows of the two parameters is not equal, the longer number of rows is used As an output
result, short parameters that are insufficient are filled continuously to the same length with the last bit.can be used for functions in expressions
Function explanation and usage example after the function
Type conversion function
x2i08 //Convert any data type to a one-byte signed integer x2i08(type), x2i08(2.0)
x2i16 //Convert any data type to a two-byte signed integer x2i16(type), x2i16(2.0)
x2i32 //Convert any data type to a four-byte signed integer x2i32(type), x2i32(2.0)
x2i64 //Convert any data type to an eight-byte signed integer x2i64(type), x2i64(2.0)
x2u08 //Convert any data type to a one-byte unsigned integer x2u08(type), x2u08(2.0)
x2u16 //Convert any data type to a two-byte unsigned integer x2u16(type), x2u16(2.0)
x2u32 //Convert any data type to a four-byte unsigned integer x2u32(type), x2u32(2.0)
x2u64 //Convert any data type to an eight-byte unsigned integer x2u64(type), x2u64(2.0)
x2flt //Convert any data type to a four-byte floating point number x2flt(id), x2flt(10)
x2dbl //Convert any data type to an eight-byte floating point number x2dbl(id), x2dbl(10)
x2str04 //Convert any data type to a four-byte string x2str04(id), x2str04(10)
x2str08 //Convert any data type to an eight-byte string x2str08(id), x2str08(10)
x2str16 //Convert any data type to a sixteen-byte string x2str16(id), x2str16(10)
x2str32 //Convert any data type to a 32-byte string x2str32(id), x2str32(10)
x2str64 //Convert any data type to a 64-byte string x2str64(id), x2str64(10)
x2str128 //Convert any data type to a 128-byte string x2str128(id), x2str128(10)
x2str256 //Convert any data type to a 256-byte string x2str256(id), x2str256(10)
x2date //Convert any data type to date x2date(b_date),x2date("2012-03-05")
x2time //Convert any data type to time x2time(b_time),x2time("18:35:24")
x2datetime //Convert any data type to date and time x2datetime(b_dt),x2datetime("2012-03-05 18:35:24")
Aggregate function
sum //Find the sum of a column sum(id), sum(1.0)
product //Find the product of a certain column product(id), product(1.0)
min //Find the minimum value of a column min(id), min(1.0)
max //Find the maximum value of a column max(id), max(1.0)
avg //Find the mean of a column avg(id), avg(1.0)
count //Find the total number of a column count(id), count(1.0)
sort //Sort a column sort(id)
unique //Unique a column unique(sort(id))
count_unique //Find the unique count of a column count_unique(sort(id))
Range function
first //Take the first element of a column first(id)
last //Take the last element of a column last(id)
first_k //Take the first k elements of a certai first_k(id,10)
last_k //Take the last k elements of a certain co last_k(id,20)
range //Take a column of interval elements range(id,1,5)
nth //Take the nth element of a certain column nth(id,10)
String function
lcase //Convert the string to lowercase lcase("Abd")
ucase //Convert the string to uppercase ucase("abc")
concat //Connect two strings concat("abc","012")
length //Find the string length length("NAME")
all_case //Output all case string all_case("Insert")
starts //Output is string start with starts(name, "Jim")
contain //Determine whether the string contains the target contain(desc, "error")
ends //Output is string end with ends(val, "es")
substr //Take the string starting from the index to a fixed number of substrings substr(name, 1, 4)
replace //Replace the substring of the string with the new string replace(name, 2, 4, "abc")
trim_l //Move out consecutive spaces on the left side of the string trim_l(name)
trim_r //Move out consecutive spaces on the right side of the string trim_r(name)
trim //Move out consecutive spaces on both sides of the string trim(name)
reg_match //Regular expression matching (using ECMA-262 (2011) standard) reg_match(id,"[1-9]+.*")
fuzzy_match //Fuzzy Retrieval of Differences in Matching Characters fuzzy_match(id,"what"),fuzzy_match(type,"system", 5)
Mathematical function
abs //Find the absolute value of the value abs(value)
ceil //Find the smallest integer that is not less than the given valu ceil(value)
floor //Find the largest integer that is not greater than the give floor(value)
round //Find the rounded value of the value round(3.4)
exp //Find the definite power of e exp(value)
pow //The power of the value pow(id,2.0)
pi //Constant value Π pi()
sqrt //Find the square root of the value sqrt(value)
log //Find the natural logarithm of the value log(value)
log2 //Find the base-2 logarithm of the value log2(value)
log10 //Find the base-10 logarithm of the value log10(value)
log1p //Find the natural (base e) logarithm of 1+value log1p(value)
sin //Find the sine of the value sin(value)
cos //Find the cosine of the value cos(value)
tan //Find the tangent of the value tan(value)
asin //Find the arc sine of the value asin(value)
acos //Find the arc cosine of the value acos(value)
atan //Find the arc tangent of the value atan(value)
e //The mathematical constant e e()
Internal function
raw2hex //Memory hexadecimal display raw2hex(id)
row_id //Output line number row_id()
id //Output internal id id()
now_id //Output max id that not used. now_id()
hash_passwd //Output the string's hash password hash_passwd("mypass")
Statistical function
var //Output variance var(id)
stddev //Standard deviation stddev(id)
Sequence function
seq //Output sequence 0 to n seq(10), seq(count(id)), seq(3)*3
rand //Output n random numbers from 0 rand(10)
constants //Output n constants constants(1,10), constants("sss",10)
Date function
last_day //Return to the last day of the date month last_day(date())
is_leap //Return whether it is a leap year is_leap(date())
now //Return the current date and time now()
date //Return the current date date()
time //Return the current time time()
add_day //Return the time or date time after n days add_day(now(),100)
add_nanosec //Return the time or date time after n nanoseconds add_nanosec(time(),10000000)
sub_day //Return the time or date and time n days ago sub_day(now(),100)
sub_nanosec //Return the time or date and time before n nanoseconds sub_nanosec(time(),10000000)
day_diff //Return the difference between the date or date time day_diff(d,date())
nanosec_diff //Return the difference in nanoseconds between time or date and time nanosec_diff(t,time())
year_of //Return the year part of the date or date time year_of(date())
month_of //Return the month part of the date or date time month_of(date())
day_of //Return the day part of the date or date time day_of(date())
hour_of //Return the time part of the time or date time hour_of(time())
minute_of //Returns the minute part of the time or date time minute_of(time())
second_of //Returns the second part of the time or date time second_of(time())
nanosec_of //Return the nanosecond part of the time or datetime nanosec_of(time())
date_of //Return the date part of the date and time date_of(now())
time_of //Return the time part of the date and time time_of(now())
weekday //Return the day of the date or date and time (0 is Monday) weekday(now())
weekday_name //Return the name of the week of the date or date and time weekday_name(now())
weekday_cname //Return the Chinese name of the week of the date or date and time weekday_cname(now())The where condition allows the use of relational operations, range operations, in operations and logical operations
The where expression is different from the standard SQL processing flow. The SCTwhere condition part only represents the conditional statement that can be directly retrieved from the data table, and the corresponding complex operations need to be completed with the help of data post processing. This processing can more clearly see whether a SQL statement uses index conditions and post-processing.
id>=10 //Greater than or equal to logic operation
id>=all (select id from t2) //The logical operation of all results greater than or equal to the subquery
id==any (select id from t2) //Logical operation equal to any result of subquery
id==any (1,3,5,7) //Logical operation equal to any result of the set
id==10 //Equal to logic operation
id!=10 //Not equal to logical operation
id>=10&&id<=20 //Logic AND operation between relational operations
id>=10||(id < 5&& id > 1) //Logical OR operation between relational operations
10 <= id <= 20 //Relational operation is less than or equal to, less than or equal to operation
10 < id <= 20 //Less than, less than or equal to relational operations
first //The first of the range operation
last //The last of the range operation
first 100 //The first 100 of the range operation
last 100 //The last 100 of the range operation
range 10 100 //The 10th to 100th range operation
nth 10 //The 10th number of the range operation
id max //The largest value range operation
id min //The smallest value range operation
id max 100 //The largest first 100 of the value range operation
id min 100 //The smallest first 100 of the value range operation
id in (1,2,3,4,7) //in operation takes the id of 1, 2, 3, 4, 7
id in (select id from t2); //Retrieve the result of id belonging to the sub-expression
id not in (select id from t2); //Remove the result that id does not belong to the sub-expression
Note that the following are invalid where conditions
10 < id //The field name id should be placed firstsystem composition
SCT database contains two modes of executable programs and development SDK and examples.
Run the corresponding sct_local.exe directly in the local mode; after entering the execution environment, enter the "help" command to view the help information or directly enter the sql statement to execute. For the corresponding sql specifications, see the sql quick guide section .
The local mode uses sct_ldb.toml as the configuration file. For the toml file specification, please refer to related specifications (Note The configuration file used by Number Silkworm does not support toml table array). In the configuration file, max_cache_level is the most important cache memory usage parameter. It represents the number of levels of the BST tree cache. The minimum is 0, which means that memory is not used.
The auto_cache parameter indicates whether the cache data is automatically loaded when the database is started. By default, it is automatically cached. auto_cache_ratio indicates the maximum height ratio of the cache, 0 means no cache at all, and 1 means full cache. Note that the cache will take a certain amount of time, and it is recommended not to cache an excessively large height ratio for relatively large data tables.
The cache_table parameter indicates that the cache size is set for a special table name.
The big_csv segment external_sort_count represents the number of outbound rows at one time when the load big_csv command is used, and csv_read_once_size represents the size of the csv file that is read at one time. For machines with smaller physical memory, you can adjust the corresponding parameters. The larger the parameter, the faster the load command will be executed.
The network mode server is sct_s.exe, and the server uses sct_rdb.toml as the configuration file. The configuration content is the binding port and user group information. Other configuration information such as cache is the same as the local mode database configuration content.
The network mode client is sct_c.exe, the client must specify the user name, password and optional IP port to run. The following is a valid running example.
sct_c.exe user user_pwd
sct_c.exe user user_pwd 192.168.1.11 55555
The default network mode verification policy is that the user name and password must be specified for the first login, 3 errors stop for 1 minute, the next 2 errors stop for 30 minutes, the next error stop for 15 days, and the next 1 error stop forever until The service restarts.
The network mode communication protocol specifications are as follows:
The corresponding system file does not include the help document, and the complete help reference file is the content of this page.
sql query process
The actual storage of data is columnar storage

The SCT database data processing flow is as follows:
The content of the where statement must be the retrieval condition using the index (different from the standard SQL statement here), and the condition is applied to filter the data rows.
The row information takes out the column content and performs expression calculation to generate a data set.

The data set can be expanded horizontally and vertically (join/union) to expand into a larger single data set.

Sort, filter, group and aggregate, project, rename and recalculate several post-operations in a single set.

sort

There are five operations for filtering:
filter inner row

filter between rows, complexity n*n

filter adjacent rows

filter row range

existence/subquery filter

group

project

rename

recompute

select
Select part of the psg (similar to EBNF) grammar definition
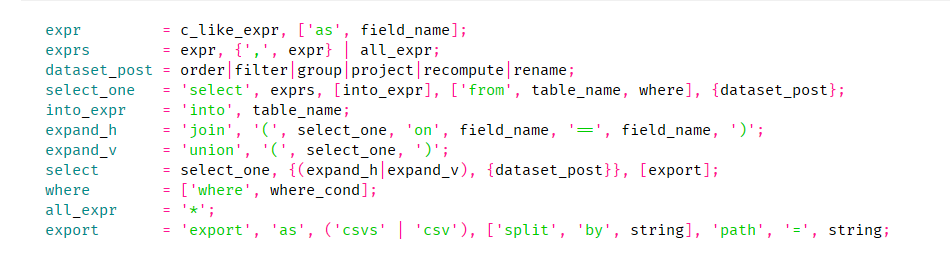
select * from table1;
//Select all fields from table1
select id from tab2;
//Select the id field from tab2
select id /sin(id) from tab2 where id < 10;
//Select the id data with id less than 10 from tab2 and find the value of id divided by sin(id)
select max(id) from tab2 where id < 10&&id > 3;
//Select the largest id greater than 3 and less than 10 from tab2
select id << 10 from tab2 where id!=3
//Select the id whose id is not equal to 3 from tab2 and shift it to the left by 10 places
select sin(id),name into t2 from t1 where id < 10;
//Select from t1 with id less than 10 and insert t2 with sin(id) and name as the column
select * from t1 where id in (select id2 from t2 where id2 > 10);
//Select from t1 when id is in t2 and when id2 is greater than 10, all of t1 in id2
select * from t1 where id < 10 order by id, name asc;
//Select from t1 when the id is less than 10 and sort the dictionary in ascending order by id and name
select * from t1 where id < 10 group sum(id) by name;
//Select from t1 when id is less than 10 and use name to group sum(id)
select * from t1 where id < 10 all_each on distinct;
//Select from t1 when the id is less than 10 and filter all rows to remove duplicates
select * from t1 where id < 10 all_each on id==_id && name==_name;
//Select from t1 when the id is less than 10 and filter all rows with the same id and the same name,_ means each
of the previous set
select * from t1 where id < 10 adj on id>_id && name==_name;
//Select from t1 when the id is less than 10, then filter the row neighbor id greater than the previous data with
the same id and name,_ means the previous line
select * from t1 where id < 10 inner on id==name;
//Select from t1 when the id is less than 10 and filter the data with the same id and name in the row
select * from t1 where id < 10 first;
//Select from t1 when the id is less than 10 and filter to keep the first row
select * from t1 where id < 10 first 30;
//Select from t1 when the id is less than 10, filter and keep the first 30 rows
select * from t1 where id < 10 range 30 40;
//Select from t1 when the id is less than 10 to filter and retain the data in the range of 30 to 40 rows
select id1,name from t1 where id < 10exists (select id from t2 where id==id1);
//Select from t1 when id is less than 10 and exist in t2 id1 and name
select id as nid,name from t1 where id < 10 not exists (select id from t2 where id==nid);
//Select from t1 when id is less than 10 and there is no nid and name with id equal to nid in t2
select * from t1 where id < 10 recompute id=id+10;
//Select from t1 when id is less than 10 and recalculate id equal to id plus 10.
select * from t1 where id < 10 recompute id+=10,name=x2str(id);
//Select from t1 when the id is less than 10, recalculate the column id equal to id plus 10, name equal to the id
converted into a string
select * from t1 where id < 10 project except id;
//Select from t1 when the id is less than 10 all post-projection to retain the column data except id
select * from t1 where id < 10 project id;
//Select all post-projection columns whose id is less than 10 from t1 to retain column id
select * from t1 where id < 10 rename id newid;
//Select from t1 when the id is less than 10 and rename the id to newid
select * from t1 where id < 10 project id range 30 40 group sum(id) by id order by id rand rename id newid;
//Select all post-projection id from t1 when id is less than 10, filter data in the range of 30 to 40, use id to
group sum(id), sort by id randomly, rename id to newid
select * from t1 where id1 < 10 join (select * from t2 where id < 20 on id1==id2);
//Select from t1 when id1 is less than 10 and expand horizontally. Select from t2 when id2 is less than 20 and id1 is
equal to id2.
select sin(seq(count(id))+1), id, name from t1 where id < 10 union (select * from t2 where id < 10);
//Select from t1 when id is less than 10 sin(seq(count(id))+1), id, name vertical expansion, select all the id less
than 10 from t2
select sin(id) as sinid,id from t1 where id < 10 inner on sinid < id;
//Select sin(id) with id less than 10 from t1 as sinid and id filter to keep the data with sinid less than id in
the row
select * from t1 export as csv split by "," path = "t1.csv";
//Select all fields of t1 to export to t1.csv file separated by commasinsert
insert into tab1 (name,id) values("Tom",100); //Single insert
insert into tab2 (val,type)values(1.00,1)(2.00,2)(3.00,3); //Multiple inserts
insert into tab2 (val,type)values(1.00,1),(2.00,2),(3.00,3); //Multiple inserts
insert into t2 (id,name) select id,name from t1; //Insert subquery result
insert into t2 (id,name) select seq(10)+1,"name"+x2str(seq(10)+1); //Insert custom data
Note that SCT database does not support null fields, so insert must specify a value for each fielddelete
delete from tab1 where id < 10; //Delete all data with id less than 10 from tab1update
update tab1 set name="Tom",id=10 where id==5;
//Update the name field with id equal to 5 in tab1 to Tom's id to 10.create
create table tab1 (id u08 (false, false));
//Create table tab1, the initial field is id type is one-byte unsigned integer, no repetition is allowed
create table tab1 (val float(),name string08(true));
//Create table tab1, the initial field val is floating-point type and no repetition is allowed, and the field name
is string type and repetition is allowed
Note that the second parameter of the current field is a reserved parameter and has no effect in actual usealter
alter table tab1 add id u08 (false, false); //Add id field in tab1
alter table tab1 modify id u08 (false, false); //Modify the id field type in tab1, the modification will clear
the previous field data, please backup
alter table tab1 rename id newid; //Rename the id field in tab1 to newid
alter table tab1 drop id; //Delete the id field in tab1drop
drop table tab1 //Delete table tab1truncate
truncate table t1; //Quickly clear t1 and retain data structureimport
The import csv/csvs command provides the data import function (csv/csvs has the same meaning as in load), and reads
one line of insert at a time.
Import retains the contents of the original table, the speed is slow, and log records are performed every time.
Note: The table must exist when using import
import t1 from csv split by "\t" path="t1.csv" //Import from t1.csv to t1 with \t as the separator
import t1 from csvs path="t1.csvs" //Import t1.csvs into t1 (csvs file indicates that the string
is converted to ASCII code hexadecimal characters)load
The SCT database uses csv/csvs as exchange files. The csv/csvs file uses \n as the end of the line and comma (,) as
the default separator; the first line is the field name, and all other characters are the field content.The number
of fields is the same, otherwise it may cause data consistency errors. Unlike normal csv, SCT csv/csvs string does
not need double quotes.
The csvs file converts the string field into the corresponding ascii hexadecimal (raw2hex function) string. Used to
avoid strings containing \n and separators.
load big_csv/big_csvs/csv/csvs Load the corresponding file. Among them, load csv/csvs directly reads all file lines
to ensure sufficient memory.
Load big_csv/big_csvs reads about csv_read_once_size the entire number of rows each time, extracts the
corresponding data to generate individual field data, and then uses the external row, and finally directly
generates the data.Suitable for files with a particularly large amount of data. The following file names will be
generated during the generation process (assuming id is the field name and the file name is w.csv):
id_from_csv_w.csv
id_from_csv_w.csv_with_row_id
id_from_csv_w.csv_with_row_id_sorted
id_from_csv_w.csv__with_row_id_sorted_svt
id_from_csv_w.csv_for_index
id_from_csv_w.csv_for_index_sorted
id_from_csv_w.csv_for_index_sorted_svt
Waipai generates the following files:
0,1,2,3,4,.., merging_file
Please make sure that the program directory does not contain these files, and ensure that a certain amount of
memory (about 2G) is available.
The difference between load and import:
Load does not retain the original table content, import retains the original table content
Load directly constructs the underlying structure, import inserts data strictly according to the process
Load is faster, suitable for large data migration, import is suitable for small amount of data
Note: The table must exist when using load
load t1 from csv split by "\t" path="t1.csv" //Import t1.csv into t1 with \t as the separator
load t1 from csvs path="t1.csvs" //Import t1.csvs into t1 (csvs file indicates that the string
is converted to ASCII code hexadecimal characters)
load t1 from big_csv split by "\t" path="t1.csv" //Import t1.csv into t1 with \t as the separator
load t1 from big_csvs path="t1.csvs" //Import t1.csvs into t1field name
SCT database field names can be up to 256 characters long, and each table can have up to 4096 fields. The following
are valid field names
Note: When the field name is saved as a local file, it is limited by the system file name. Some special characters
or special file names may not be supported. For detailed restrictions, please refer to the relevant system
description
abc
abc0123
ABC_abc
[Valid non-@string (see string)]table name
SCT database table names can be up to 256 characters long, and each database can have up to 4096 tables. The
following are valid table names
Note: When the table name is saved as a local file, it is limited by the system file name. Some special characters
or special file names may not be supported. For detailed restrictions, please refer to the relevant system
instructions
abc
abc0123
ABC_abc
[Valid non-@string (see string)]rows_of
rows_of tab1 //Get the number of rows in tab1cols_of
cols_of tab1 //Get the number of columns in tab1fields_of
fields_of tab1 //Get the field name of tab1show tables
show tables //Get all table names in the databaseexec
exec "data.sql" //Execute all statements in the sql fileatom_exec
atom_exec insert into t1 (id,name) select 1,"sss";delete from t1; commit
//Transactional execution of multiple statements with ";" as the interval and ending with commit (the isolation
level is the highest level, generally speaking, either all succeed or all fail, multi-statements only support
insert, update, delete)optimization suggestion
SCT database uses BST as an index internally. When querying for each column, the data is retrieved through the BST tree to construct query results, which is very suitable for small-scale interval queries; the content of the where statement is the first-level filter condition of the search condition, which determines the output row The most important part of the number, the query conditions should give priority to ensuring that the where part is fully filtered.
Where query conditions are given priority to use a <=id <=b instead of id>= a&&id <=b. The former will directly use the internal interval algorithm to complete, the latter will query the two parts of the interval separately for collection Intersection operation.
Use && in preference for where conditions, and try to avoid using || logical operations.
Try not to use != expressions in where conditions.
Use rows_of first to get the number of rows in the table, not the count field.
For the low effective data of the big data table, the query filter in is preferred for the initial filtering.
For large data sets, multiple valid data can be filtered according to conditions using exists.
When sql is parsed, the parsed syntax tree will be cached. It is recommended to merge insert statements as much as possible to avoid multiple parsing.
Use the where statement to filter the data set first, and reduce the use of data set post-operation processing.
The sql statement expression evaluation is slower than the C language, try to avoid using a large amount of expression processing; a large amount of expression processing can be reprocessed in C language after the parsed expression is obtained.
When importing large quantities of data, use the load big_csv command first, the second best use the load csv statement, and finally use the import statement, try not to use exec and insert statements.
development instruction
SCT database is written in C++, and the network side provides packaged C/C++/Java(include JDBC)/Python language interface. The development library is located in the sdk directory.
The Windows dynamic link library of vs2019 is provided in the installation package, located in the sdk/dll directory. The header file is located in the sdk/inc directory.
Basic functions include connecting, exiting the server, executing SQL statements, and obtaining data set row and column information and value information. The following is a complete C language interface example (located in sdk/sql_lib_sample.c):
#include <stdlib.h>
#include <stdio.h>
#include "sql_lib.h"
void print_bymyself(void* d) {
int r = rows_of(d);
int c = cols_of(d);
printf("\n");
for (size_t i = 0; i < c; ++i) {
int s = 0;
const char* n = col_name(&s, d, i);
printf("%.*s ", s, n);
}
printf("\n");
for (size_t i = 0; i < r; ++i) {
for (size_t j = 0; j < c; ++j) {
void* v = at(i, j, d);
int g = val_sign(v); int s = val_size(v); int t = val_type(v);
if (t == VAL_TYPE_I) {
if (s == VAL_SIZE_1) {
printf(" %d", g == VAL_SIGN ? as_int8_t(v) : as_uint8_t(v));
} else if (s == VAL_SIZE_2) {
printf(" %d", g == VAL_SIGN ? as_int16_t(v) : as_uint16_t(v));
} else if (s == VAL_SIZE_4) {
printf(" %d", g == VAL_SIGN ? as_int32_t(v) : as_uint32_t(v));
} else {
printf(" %d", g == VAL_SIGN ? as_int64_t(v) : as_uint64_t(v));
}
} else if (t == VAL_TYPE_F) {
printf(" %f", s == VAL_SIZE_4 ? as_float(v) : as_double(v));
} else if (t == VAL_TYPE_S){
char* p = NULL; int c = 0;
as_str(&p, &c, v);
if( p != NULL ){
printf(" %.*s", c, p);
free(p);
}
} else {}
}
printf("\n");
}
}
int main(int argc, char** argv) {
if(!connect_to_server("192.168.5.10", 55555, "user", "user")){ return -1; }
void* d = exec("create table tab1 (id u32(true), name string04());");
if (d == NULL) { printf("execute sql failed\n"); return 0; }
del_datas(d);
d = exec("insert into tab1 (id,name) select seq(1000), x2str(seq(1000)+10);");
if (d == NULL) { printf("execute sql failed\n"); return 0; }
del_datas(d);
d = exec("select id,name from tab1 where id < 10;");
if( d == NULL ){ printf("execute sql failed\n"); return 0; }
print(d);
print_bymyself(d);
del_datas(d);
d = exec("drop table tab1;");
exit_to_server();
return 0;
}
common problem
Network connection is unsuccessful
1. The local end of SCT does not support network functions. Make sure that the server is turned on when using the client to connect; in the default configuration file, sct_mdb.toml, the server section
port specifies the local link port. Make sure that the corresponding port is not occupied.
2. SCT uses login verification strategy. Ensure that the number of operations does not exceed the threshold requirement.
where statement is not supported
SCT where statements are not compatible with standard SQL content. Related statements such as inline condition filtering (id==name), exist, group by, etc. need to be converted to data post-processing operations。
Function reg_match is not working properly
The SCT regular expression parsing library is an implementation of ECMA-262 (version 2011), compatible with most regular expression grammars, and the addition of \h matches Chinese \H matches non-Chinese boundary characters.
In order to avoid performance pitfalls under special circumstances, the regular expression library uses non-backtracking matching by default, that is, .* will match all, and should be avoided when using it.
fuzzy_match is particularly slow
The default fuzzy matching will match all matching results with a difference of less than half the length, so the matching algorithm is not suitable for longer strings.
Error feedback
SCT database has been thoroughly and fully tested, but some unknown errors may still be unavoidable. For related errors, please send the problem description to admin@shucantech.com.